Table of Contents
MUDA is μ-CUDA, yet another painless CUDA programming paradigm.
COVER THE LAST MILE OF CUDA
Introduction
What is muda?
- Header-only library right out of the box
- Depends only on CUDA and standard libraries
- Improve readability, maintainability, security, and debugging efficiency of CUDA code.
- Reduce the difficulty of building CUDA Graphs and increase automation.
Why muda?
Think that you wanna try a new idea or implement a demo with CUDA. If the demo works well, you want to embed it into your project quickly. But you find that using CUDA directly will be a catastrophic disaster.
Coding with C-API CUDA, you will be buried in irrelevant details, and the information density of the code is very low, which means that you need to write a lot of redundant code to achieve a simple function. Less is more, right?
Debugging the GPU code is a nightmare. How much time do you spend on those weird Error Codes from CUDA, and finally find it's an illegal memory access?

Using a GPU Debugger when something goes wrong may be an approach. But the best way is to prevent bugs from happening, right? Most of the time, automatic range checking is all we want. It's a pretty fantasy that someone tells you, "Hey Bro, at `Block 103, Thread 45`, in kernel named `set_up_array`, the buffer named `array` goes out of range because your index is `100` while the array size is `96`." After that, it exits the kernel and stops the program for you to prevent later chained dummy bugs from producing confusing debug information.
It is muda!
If you access memory resource using a MUDA Viewer. Dear muda will tell you all about that.
MUDA also provides an elegant way to create and update CUDA Graph, called MUDA ComputeGraph.
- Users almost take only a bit of effort to switch from the Stream-Base Launch Mode to Graph Launch Mode.
- Updating the node parameters and shared resources in CUDA Graphs becomes intuitive, safe, and efficient.
Simple to extend.
- User can obey the primary interface of muda to define their own object to reuse the MUDA facility
- Almost all "Resource View Type" can be used directly in the MUDA
ComputeGraph.
A substitution of thrust?
Nop! MUDA is a supplement of thrust!
Thrust is a C++ template library for CUDA based on the Standard Template Library (STL). Thrust allows you to implement high-performance parallel applications with minimal programming effort through a high-level interface that is fully interoperable with CUDA C.
Using iterators to prevent range error is a high-level approach. However, we still need to access the memory manually in our own kernel, no matter whether using raw cuda kernel launch <<<>>> or using thrust agent kernel (most of the time, using a thrust::counting_iterator in a thrust::for_each algorithm).
So, I think MUDA is a mid-level approach. We have the same purpose but different levels and aim at different problems. Feel comfortable to use them together!
Here is an example for using Thrust and MUDA together.
Overview
This is a quick overview of some muda APIs.
You can check it to find out something useful for you. A comprehensive description of MUDA is placed at Tutorial.
Launch
Simple, self-explanatory, intellisense-friendly Launcher.
Logger
A std::cout like output stream with overload formatting.
You can define a global__device__ LoggerViewer cout and call the overloaded constructor Logger(LoggerViewer* global_viewer) to use it without any capturing, which is useful when you need to use logger in some function but don't want to put the LoggerViewer in the function parameter.
Further, you can use muda::Debug::set_sync_callback() to retrieve the output once wait() is called, as:
Buffer
A lightweight std::vector-like cuda device memory container.
In addition, 2D/3D aligned buffers are also provided.
The old data will be safely kept if you resize a 2D or 3D buffer. If you don't want to keep the old data, use .clear() before your .resize(). The result of the above chain of 2D buffer resizing is shown below.

Viewer In Kernel
MUDA Viewers provide safe inner-kernel memory access, which checks all input to ensure access does not go out of range and does not dereference a null pointer. If something goes wrong, they report the debug information as much as possible and trap the kernel to prevent further errors. Don't forget to fill the kernel_name() and name() out.
Event And Stream
If you don't want to launch something on the default stream, use Stream to create async streams. And you can use Event to synchronize between streams.
Asynchronous Operation
MUDA Launchers' functions are Asynchronous, meaning we need to call .wait() to synchronize it on the host, unlike some APIs such as BufferView::copy_fom. NOTE: Operations of a Launcher will be asynchronous as possible, so you should synchronize the stream by yourself, while other APIs will synchronize themselves.
Feel free to ignore Memory BufferLaunch Launcher when building your fast demo. Directly use the convenient synchronous APIs of DeviceBuffer/BufferView until you find it's the performance hotpot that will save you a lot of time.
It's a good practice to keep Launchers asynchronous while keeping other APIs synchronous, which obeys the 80/20 rule.
[Extension] Linear System Support
[We are still working on this part]
MUDA supports basic linear system operations. e.g.:
- Sparse Matrix Format Conversion
- Sparse Matrix Assembly
- Linear System Solving

The only thing you need to do is to declare a muda::LinearSystemContext.
We only allow users to assemble a Sparse Matrix from Triplet Matrix. And allow users to read from BCOOMatrix.
To assemble a Triplet Matrix, user need to use the viewer of a Triplet Matrix.
[TODO:] Later, we may involve Expression Template to strengthen the linear algebra calculation and use lazy evaluation to arrange as many element-wise/scattering operations as possible in a single kernel.
[Extension] Field Layout
MUDA now supports the SoA/AoS/AoSoA layouts. Users can switch between them seamlessly(with different builder parameters). The copy operation in all directions and layouts is well-supported.
Most of the time, AoSoA is the best layout for Vector and Matrix, with better memory coalescing and more compact memory storage. With the help of Eigen::Map<>, the read/write of a Vector/Matrix is as trivial as accessing a struct-version Vector/Matrix.
Here is a simple example of muda::Field.
Additionally, resizing a subfield will resize all the entries, and the resizing is safe; all entries will be copied to a new buffer if the new size exceeds the capacity.
It'd be useful if the topology will change in your simulation. For example, the fracture simulation always changes its tetrahedron mesh, and all attributes of particles, edges, triangles, and tetrahedra will change correspondently. It will be terrible if you resize all the attributes yourself.
Note that every FieldEntry has a View called FieldEntryView. A FieldEntryView can be regarded as a ComputeGraphVar(see below), which means FieldEntry can also be used in ComputeGraph.
Compute Graph
Define MUDA_WITH_COMPUTE_GRAPH to turn on Compute Graph support.
MUDA can generate cudaGraph nodes and dependencies from your eval() call. And the cudaGraphExec will be automatically updated (minimally) if you update a muda::ComputeGraphVar. More details in zhihu_ZH.
Define a muda compute graph:

Launch a muda compute graph:
Dynamic Parallelism
MUDA support dynamic parallelism based on MUDA ComputeGraph.

MUDA vs. CUDA
Build
Xmake
Run example:
To show all examples:
Play all examples:
Cmake
Copy Headers
Because muda is header-only, copy the src/muda/ folder to your project, set the include directory, and everything is done.
Macro
| Macro | Value | Details |
|---|---|---|
MUDA_CHECK_ON | 1(default) or 0 | MUDA_CHECK_ON=1 for turn on all muda runtime check(for safety) |
MUDA_WITH_COMPUTE_GRAPH | 1or0(default) | MUDA_WITH_COMPUTE_GRAPH=1 for turn on muda compute graph feature |
If you manually copy the header files, don't forget to define the macros yourself. If you use cmake or xmake, just set the project dependency to muda.
Tutorial
[TODO]
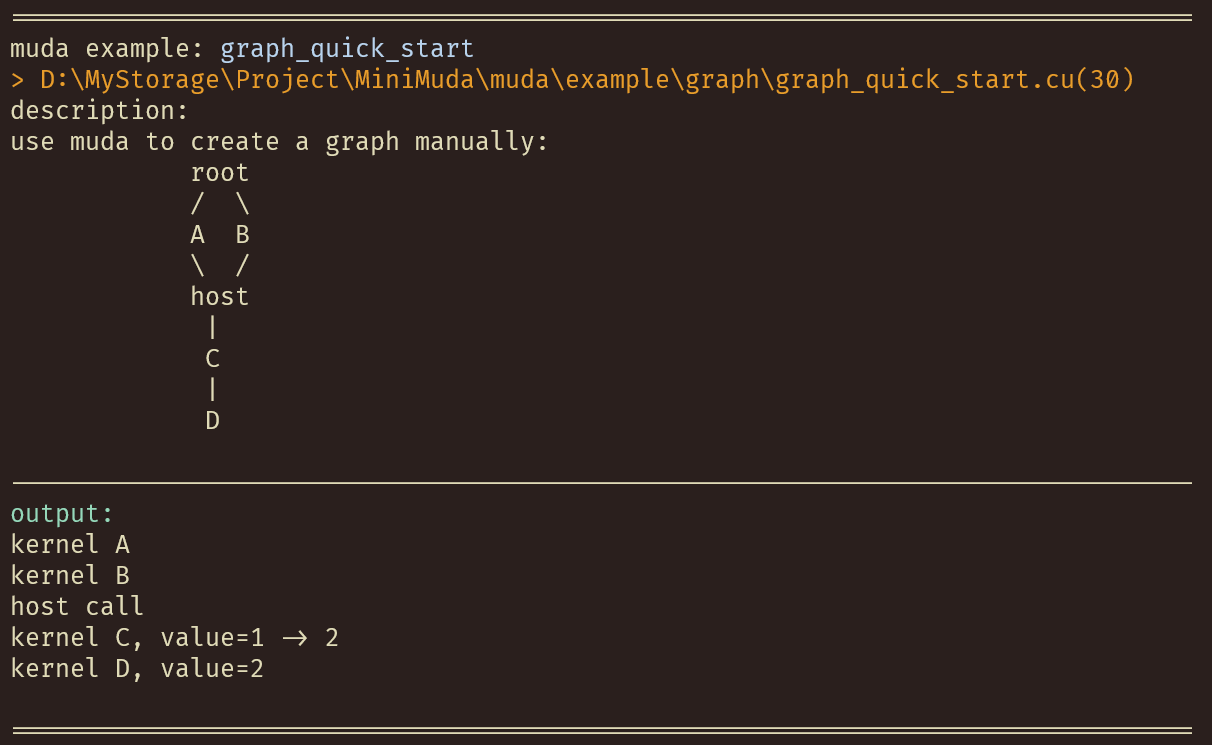
Examples
All examples in muda/example are self-explanatory, enjoy it.
Contributing
Contributions are welcome. We are looking for or are working on:
- muda development
- fancy simulation demos using muda
- better documentation of muda
Related Work
Topological braiding simulation using muda (old version)
@article{article,author = {Lu, Xinyu and Bo, Pengbo and Wang, Linqin},year = {2023},month = {07},pages = {},title = {Real-Time 3D Topological Braiding Simulation with Penetration-Free Guarantee},volume = {164},journal = {Computer-Aided Design},doi = {10.1016/j.cad.2023.103594}}